The Structure
一般位于PGDATA的这个环境变量下。以下内容以 PostgreSQL 9.6 版本为例
PG_VERSION # version file. 一个包含PostgreSQL主版本号的文件
base # use to store database file(SELECT oid, datname FROM pg_database). 包含每个数据库对应的子目录的子目录
global # under global, all the filenode is hard-code(select oid,relname,relfilenode from pg_class where relfilenode=0 order by oid). 包含集簇范围的表的子目录,比如pg_database
pg_clog # dir of transaction commit log
pg_commit_ts # 包含事务提交时间戳数据的子目录
pg_dynshmem # 包含被动态共享内存子系统所使用的文件的子目录
pg_hba.conf # client authentication config file
pg_ident.conf # user ident map file
pg_logical # 包含用于逻辑复制的状态数据的子目录
pg_multixact # 包含多事务(multi-transaction)状态数据的子目录(用于共享的行锁)
pg_notify # 包含LISTEN/NOTIFY状态数据的子目录
pg_replslot # 包含复制槽数据的子目录
pg_serial # 包含已提交的可序列化事务信息的子目录
pg_snapshots # dir of snapshot file 包含导出的快照的子目录
pg_stat # 包含用于统计子系统的永久文件的子目录
pg_stat_tmp # dir of tmp stat file 包含用于统计信息子系统的临时文件的子目录
pg_subtrans # 包含子事务状态数据的子目录
pg_tblspc # 包含指向表空间的符号链接的子目录
pg_twophase # 包含用于预备事务状态文件的子目录
pg_xlog # dir of xlog file
postgresql.auto.conf # 一个用于存储由ALTER SYSTEM 设置的配置参数的文件
postgresql.conf # config file of postmaster progress
postmaster.opts # 一个记录服务器最后一次启动时使用的命令行参数的文件
postmaster.pid # pid file of postmaster progress. 一个锁文件,记录着当前的 postmaster 进程ID(PID)、集簇数据目录路径、postmaster启动时间戳、端口号、Unix域套接字目录路径(Windows上为空)、第一个可用的listen_address(IP地址或者*,或者为空表示不在TCP上监听)以及共享内存段ID(服务器关闭后该文件不存在)
global 目录
pg_control
pg_internal.init
pg_filenode.map
1233
1232
1214
1214_vm
1214_fsm
1262
1262_fsm
1262_vm
2396_vm
1136
1136_fsm
1136_vm
1213
1213_fsm
1213_vm
1260_fsm
2396_fsm
存放的文件用于存储全局的系统表信息和全局控制信息。主要以下4种文件:
pg_control:用于存储全局控制信息pg_filenode.map:用于将当前目录下系统表的OID与具体文件名进行硬编码映射(每个用户创建的数据库目录下也有同名文件)。pg_internal.init:用于缓存系统表,加快系统表读取速度(每个用户创建的数据库目录下也有同名文件)。全局系统表文件:数字命名的文件,用于存储系统表的内容。它们在pg_class里的relfilenode都为0,是靠pg_filenode.map将OID与文件硬编码映射。(注:不是所有的系统表的relfilenode都为0)
base 目录
用于存放数据库的所有实体文件。
16384
45692
45692_fsm
45692_vm
826
826_vm
827
828
PG_VERSION # 是当前数据库数据格式对应的版本号
pg_filenode.map # 是pg_class里relfilenode为0的系统表,OID与文件的硬编码映射。
pg_internal.init # 是系统表的cache文件,用于加快读取。默认不存在,查询系统表后自动产生。
12407
12406
1
postgres=# select oid, datname from pg_database;
oid | datname
-------+-----------
12407 | postgres
16384 | zxdb
1 | template1
12406 | template0
(4 rows)
zxdb=# select oid,relfilenode,relname from pg_class where relname='t_chat_user';
oid | relfilenode | relname
-------+-------------+-------------
45692 | 45692 | t_chat_user
(1 row)
- 数据文件:以数字开头和结尾的文件。需要到pg_class里根据OID查到对应的
relfilenode来与文件名匹配的。 - 空闲空间映射表:名字以
_fsm结尾的文件。是数据文件对应的FSM(free space map)文件,用map方式来标识哪些block是空闲的。用一个Byte而不是bit来标识一个block。对于一个有N个字节的block,它在_fsm文件中第blknum个字节中记录的值是(31+N)/32。通过这种方式标识一个block空闲字节数。FSM中不是简单的数组,而是一个三层的树形结构。FSM文件是在需要用到它时才自动产生的。 - 可见性映射表文件:名字以
_vm结尾的文件。是数据文件对应的VM(visibility map)。PostgreSQL中在做多版本并发控制时是通过在元组头上标识“已无效”来实现删除或更新的,最后通过VACUUM功能来清理无效数据回收空闲空间。在做VACUUM时就使用VM开快速查找包含无效元组的block。VM仅是个简单的bitmap,一个bit对应一个block。
注:系统表分为全局系统表和库级系统表。
- 全局系统表位于
global下,如:pg_database,pg_tablespace,pg_auth_members这种存储系统级对象的表。 - 库级系统表位于
数据库目录(base)下,如:pg_type,pg_proc,pg_attribute这种存储库级对象的表。值得注意的是pg_class位于库级目录的里,但也包含全局系统表信息,因此研发或运维人员在改动全局系统表信息时需要注意。
数据库集簇(cluster)
PostgreSQL安装完成后,在做任何其他事情之前,必须先使用initdb程序初始化磁盘上的数据存储区,即数据集簇,由PostgreSQL管理的用户数据库以及系统数据库总称为数据集簇。在PostgreSQL的实现中,数据库就是磁盘上一些文件的集合,只不过这些文件有特定的文件名、存储位置等,并且有些文件之间会相互关联。默认情况下,PostgreSQL的所有数据都存储在其数据目录里,这个数据目录通常会用环境变量PGDATA来引用。
在PostgreSQL中,对象标识符(OID)用来在整个数据集簇中唯一地标识一个数据库对象,这个对象可以是数据库、表、索引、视图、元组、类型等。PostgreSQL提供了Oid数据类型来表示OID,它实际上是一个无符号整数。OID通常是从1开始分配,但在初始化数据集簇时,会先将一部分OID分配给系统表、系统表元组、系统表上的索引等数据库对象,这一部分OID可以在系统表所对应的头文件中找到。同时,为了给后续版本留下扩展的余地,初始化数据集簇时还会预留一部分OID资源。这样,在系统运行时可分配的OID资源实际是从16384开始的。
系统数据库
在创建数据集簇之后,该集簇中默认包含三个系统数据库template1、template0和postgres。其中template0和postgres都是在初始化过程中从template1拷贝而来的。
template1和template0数据库用于创建数据库。PostgreSQL中采用从模板数据库复制的方式来创建新的数据库,在创建数据库的命令中可以用“-T”选项来指定以哪个数据库为模板来创建新数据库。
template1数据库是创建数据库命令默认的模板,也就是说通过不带“-T”选项的命令创建的用户数据库是和template1一模一样的。template1是可以修改的,如果对template1进行了修改,那么在修改之后创建的用户数据库中也能体现出这些修改的结果。template1的存在允许用户可以制作一个自定义的模板数据库,在其中用户可以创建一些应用需要的表、数据、索引等,在日后需要多次创建相同内容的数据库时,都可以用template1作为模板生成。
由于template1的内容有可能被用户修改,因此为了满足用户创建一个“干净”数据库的需求,PostgreSQL提供了template0数据库作为最初始的备份数据,当需要时可以用template0作为模板生成“干净”的数据库。
而第三个初始数据库postgres用于给初始用户提供一个可连接的数据库,就像Linux系统中一个用户的主目录一样。
上述系统数据库都是可以删除的,但是两个模板数据库在删除之前必须将其在pg_database中元组的datistemplate属性改为FALSE,否则删除时会提示“不能删除一个模板数据库”。
进程结构
守护进程postmaster
- 它是一个运行在服务器上的总控进程,负责整个系统的启动和关闭,并且在服务进程出现错误时完成系统的恢复。
- 它管理数据库文件、监听并接受来自客户端(psql,jdbc等)的连接请求,并且
为客户端连接请求fork一个Postgres服务进程,来代表客户端在数据库上执行各种命令。 - 它还管理与数据库运行相关的辅助进程。
用户可以使用postmaster、postgres或者pg_ctl命令启动Postmaster。PostgreSQL采用C/S模式,系统为每个客户端分配一个服务进程。Postmaster就像一个处理客户端请求的调度中心。前端应用欲访问某一数据库时,就调用接口库(比如ODBC、libpq)把用户的请求通过网络发给守护进程Postmaster。Postmaster将启动一个新的服务进程Postgres为用户服务,此后前端进程和服务进程不再通过Postmaster而是直接进行通信。
服务进程Postgres
服务进程Postgres接受并执行客户端发送的命令(交互式SQL查询)。它在底层模块(如存储、事务管理、索引等)之上调用各个主要的功能模块(如编译器、优化器、执行器等),完成客户端的各种数据库操作,并返回执行结果。客户端每创建一个数据库连接,postmaster生成一个postgres服务器进程,直接接受用户的命令进行编译执行,并将结果返回给用户。如此循环,直到用户断开连接。 服务器进程通过信号量和共享内存来相互通信。
辅助进程(分别为实现不同功能)
root@5b577c79978b:/# ps aux|grep post
postgres 1 0.0 0.9 234732 20384 ? Ss 14:09 0:00 postgres
postgres 24 0.0 0.2 234732 4148 ? Ss 14:09 0:00 postgres: checkpointer process
postgres 25 0.0 0.2 234732 4148 ? Ss 14:09 0:00 postgres: writer process
postgres 26 0.0 0.2 234732 4148 ? Ss 14:09 0:00 postgres: wal writer process
postgres 27 0.0 0.3 235156 7008 ? Ss 14:09 0:00 postgres: autovacuum launcher process
postgres 28 0.0 0.2 89864 4368 ? Ss 14:09 0:00 postgres: stats collector process
- 系统日志进程SysLogger
- 后台写进程bgWriter
- 预写式日志写进程WalWriter
- 预写式日志归档进程pg_archive
- 系统自动清理进程AutoVacuum:将自动定时整理(清理)外存中的数据空间。
- 统计数据收集进程pg_state:将自动统计系统运行中的一些动态信息。
进程结构再剖析
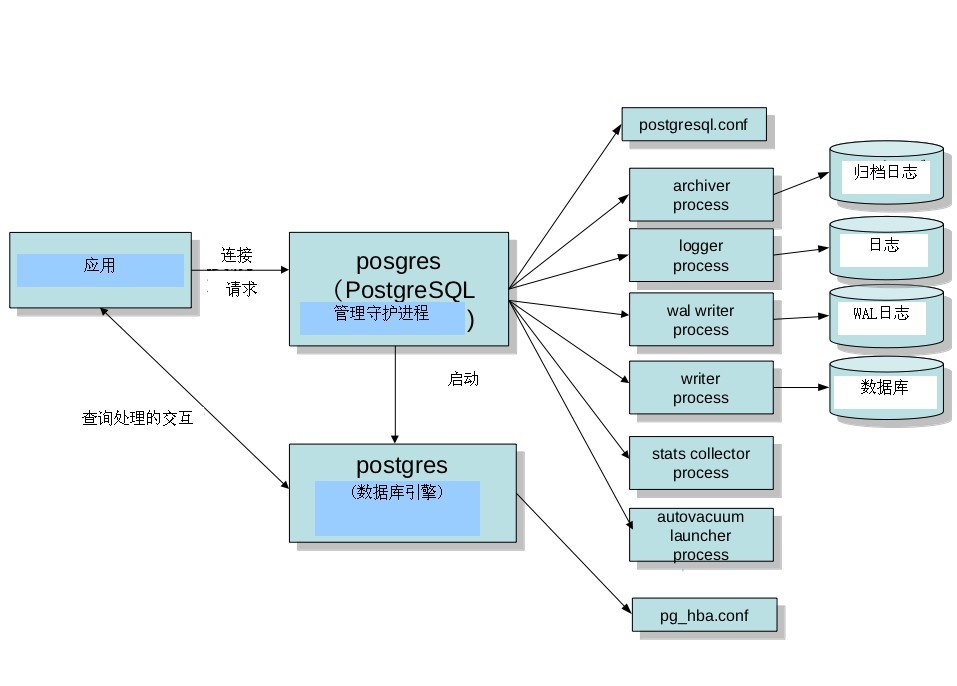
Potgres(常驻进程)
管理后端的常驻进程,也称为’postmaster’。其默认监听UNIX Domain Socket和TCP/IP的5432端口,等待来自前端的的连接处理。监听的端口号可以在PostgreSQL的设置文件postgresql.conf里面可以改。
一旦有前端连接过来,postgres会通过fork(2)生成子进程。没有Fork(2)的windows平台的话,则利用createProcess()生成新的进程。这种情形的话,和fork(2)不同的是,父进程的数据不会被继承过来,所以需要利用共享内存把父进程的数据继承过来。
Postgres(子进程)
子进程根据pg_hba.conf定义的安全策略来判断是否允许进行连接,根据策略,会拒绝某些特定的IP及网络,或者也可以只允许某些特定的用户或者对某些数据库进行连接。
Postgres会接受前端过来的查询,然后对数据库进行检索,最好把结果返回,有时也会对数据库进行更新。更新的数据同时还会记录在事务日志里面(PostgreSQL称为WAL日志),这个主要是当停电的时候,服务器宕机,重新启动的时候进行恢复处理的时候使用的。另外,把日志归档保存起来,可在需要进行恢复的时候使用。在PostgreSQL 9.0 以后,通过把WAL日志传送其他的postgreSQL,可以实时得进行数据库复制,这就是所谓的’数据库复制’功能。
其他进程
Postgres之外还有一些辅助的进程。这些进程都是由常驻postgres启动的进程。
Writer process: 在适当的时间点把共享内存上的缓存写往磁盘。
- 通过这个进程,可以防止在检查点的时候(checkpoint),大量的往磁盘写而导致性能恶化,使得服务器可以保持比较稳定的性能。Background writer起来以后就一直常驻内存,但是并非一直在工作,它会在工作一段时间后进行休眠,休眠的时间间隔通过
postgresql.conf里面的参数bgwriter_delay设置,默认是200微秒。 - 这个进程的另外一个重要的功能是定期执行检查点(checkpoint)。检查点的时候,会把共享内存上的缓存内容往数据库文件写,使得内存和文件的状态一致。通过这样,可以在系统崩溃的时候可以缩短从WAL恢复的时间,另外也可以防止WAL无限的增长。可以通过
postgresql.conf的checkpoint_segments、checkpoint_timeout指定执行检查点的时间间隔。
WAL writer process: 把共享内存上的WAL缓存在适当的时间点往磁盘写,通过这样,可以减轻后端进程在写自己的WAL缓存时的压力,提高性能。另外,非同步提交设为true的时候,可以保证在一定的时间间隔内,把WAL缓存上的内容写入WAL日志文件。
Archive process: 把WAL日志转移到归档日志里。如果保存了基础备份以及归档日志,即使实在磁盘完全损坏的时候,也可以回复数据库到最新的状态。
stats collector process: 统计信息的收集进程。收集好统计表的访问次数,磁盘的访问次数等信息。收集到的信息除了能被autovaccum利用,还可以给其他数据库管理员作为数据库管理的参考信息。
Logger process: 把postgresql的活动状态写到日志信息文件(并非事务日志),在指定的时间间隔里面,对日志文件进行rotate.
autovacuum launcher process: Autovacuum启动进程,是依赖于postmaster间接启动vacuum进程。而其自身是不直接启动自动vacuum进程的。通过这样可以提高系统的可靠性。
autovacuum worker process: 自动vacuum进程,进程实际执行vacuum的任务。有时候会同时启动多个vacuum进程。
wal sender / wal receiver: wal sender 进程和wal receiver进程是实现postgresql流复制(streaming replication)的进程。
- Wal sender进程通过网络传送WAL日志,而其他PostgreSQL实例的wal receiver进程则接收相应的日志。
- Wal receiver进程的宿主PostgreSQL(也称为Standby)接受到WAL日志后,在自身的数据库上还原,生成一个和发送端的PostgreSQL(也称为Master)完全一样的数据库。